搞了两张3060显卡不知道干什么用,于是想到了本地部署生图,倒腾了将近一天,终于是部署好了,参考教程【保姆级教程】Linux上部署Stable Diffusion WebUI和LoRA训练,拥有你的专属图片生成模型_stable diffusion linux-CSDN博客,成功上线到我的blog中,但是为了防止有坏蛋干坏事,所以我设置了验证,联系我获取登录账密哦。
在部署和使用 Stable Diffusion WebUI 过程中,我先后遇到了代理协议冲突、Lora 模型识别异常、多显卡负载不均、生成图片灰蒙蒙等一系列问题,每一步都踩过典型 “坑点”,最终通过针对性配置逐一解决。以下是完整问题复盘与解决方案总结。
一、代理配置:从 “socks5h 协议报错” 到 HTTP 代理适配
1. 初始问题:WebUI 启动报 “Unknown scheme for proxy URL socks5h”
在通过 Clash 代理下载 CLIP 模型时,即使配置了混合端口(Mixed Port 7890),启动 WebUI 仍报错 “ValueError: Unknown scheme for proxy URL URL ('socks5h://127.0.0.1:7890')”。问题根源:Clash 的 clashctl on 命令会自动注入 socks5h 协议变量,而 WebUI 依赖的 httpx 库不兼容该协议;同时混合端口默认优先使用 socks5h,导致代理配置与 WebUI 需求冲突。
2. 解决过程:关闭自动注入 + 手动指定 HTTP 代理
第一步:停止 Clash 自动代理注入
执行
clashctl off清除socks5h残留变量,再通过unset HTTP_PROXY HTTPS_PROXY ALL_PROXY彻底删除终端代理缓存。第二步:启用 Clash HTTP 端口(替代混合模式)
在 Clash 配置中关闭混合端口(注释
mixed-port: 7890),新增port: 7890启用纯 HTTP 代理,避免协议冲突。第三步:手动配置代理变量并启动 WebUI
执行
export HTTP_PROXY="http://127.0.0.1:7890"配置代理,再通过./webui.sh -f启动,成功解决模型下载报错。
二、Lora 模型:从 “文件名错误” 到 WebUI 识别
1. 初始问题:wget 下载 Lora 后 WebUI 无法识别
通过 wget https://civitai.com/api/download/models/96736?type=Model 下载 Lora 模型后,文件名为 96736?type=Model,无 .safetensors 后缀,WebUI 左侧 Lora 面板未显示该模型。问题根源:CivitAI 下载链接含特殊字符 ?,wget 默认以 URL 最后一段作为文件名,导致缺失 WebUI 识别必需的 .safetensors 后缀。
2. 解决过程:重命名 + 规范下载命令
紧急处理:手动重命名文件
在
models/Lora目录下执行mv '96736?type=Model' 80year03.safetensors(文件名参考下载日志中的filename="80year03.safetensors"),刷新 WebUI 后成功识别。长期优化:下载时指定文件名
后续用
wget -O 目标名.safetensors 下载链接命令,例如wget -O bl5_v10.safetensors "https://civitai-delivery-worker-prod.xxx",直接生成带正确后缀的文件,避免二次操作。
三、多显卡配置:从 “单卡满载” 到双 RTX 3060 协同
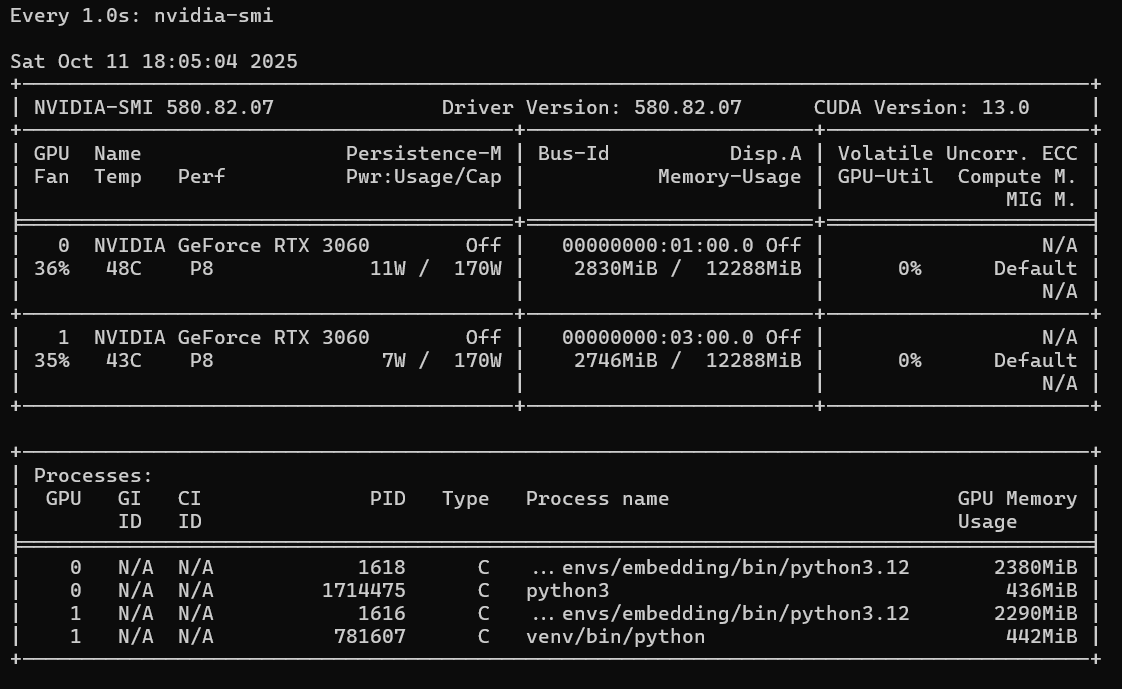
1. 初始问题:双 RTX 3060 仅主卡(GPU 0)工作
配置 export CUDA_VISIBLE_DEVICES=0,1 后,启动 WebUI 仍只有 GPU 0 处于 100% 负载(显存占用 6GB+),GPU 1 始终空闲(显存占用 2.2GB,使用率 0%)。问题根源:
WebUI 默认不自动支持多卡并行,
CUDA_VISIBLE_DEVICES=0,1仅让程序 “看到” 双卡,不会主动拆分负载;非官方 WebUI 分支(v1.10.1)缺失
--multi-gpu参数,无法通过常规参数启用多卡;GPU 1 被无关
python3.12进程占用(2290MiB 显存),无剩余空间加载模型层。
2. 解决过程:清理进程 + 强制模型拆分
第一步:清理 GPU 1 占用进程
执行
ps -p 1616 -o cmd确认无关进程,再用kill -9 1616杀掉,释放显存(GPU 1 显存降至 100MiB 以下)。第二步:用
--lowvram参数强制拆分启动命令改为
export CUDA_VISIBLE_DEVICES=0,1 && ./webui.sh -f --xformers --lowvram,--lowvram比--medvram更激进地将模型层拆分到双卡,生成 1024x1024 图像时,GPU 1 使用率升至 50%-80%,显存占用 5GB+,实现协同工作。终极方案:修改代码强制多卡
若仍不生效,编辑
modules/sd_models.py,在load_model_weights函数中添加逻辑:将含 “transformer”“attn” 的模型层移动到 GPU 1,确保双卡均参与计算。
四、图像质量:从 “画面灰蒙蒙” 到 VAE 手动适配
1. 初始问题:生成图片色彩暗淡、发灰
使用社区微调大模型(如 bl5_v10.safetensors)时,输出图片整体偏灰,色彩饱和度低。问题根源:部分合并模型会导致内置 VAE 失效,而 WebUI 默认未启用外部 VAE,缺少色彩校正环节。
2. 解决过程:手动配置外部 VAE
第一步:下载通用 VAE 模型
从 Hugging Face 下载官方 VAE(如
vae-ft-ema-560000-ema-pruned.safetensors),适用于多数风格模型。第二步:放置并选择 VAE
将 VAE 文件放入
models/VAE目录,在 WebUI “设置 - Stable Diffusion - SD VAE” 下拉菜单选择该模型,点击 “Apply settings” 保存并刷新。补全配置:添加 VAE 快速选项
若 “SD VAE” 选项缺失,在 “设置 - User Interface-Quick settings list” 中添加
sd_vae,重启 WebUI 后即可在顶部快速切换 VAE,解决画面发灰问题。
五、总结:避坑关键要点
代理优先选 HTTP:WebUI 对
HTTP代理兼容性远高于socks5,避免因协议冲突卡壳;Lora 下载带后缀:用
wget -O指定.safetensors后缀,直接适配 WebUI 识别规则;多卡先清占用:启动前用
nvidia-smi检查双卡状态,确保无无关进程占用显存;VAE 必配外部:社区模型优先手动指定官方 VAE,避免色彩暗淡问题;
参数适配分支:非官方 WebUI 分支缺失关键参数时,用
--lowvram替代--multi-gpu,或通过代码修改实现功能。